2019. 6. 25. 17:41ㆍ해보자/Kafka
자 이제 해보자
https://kafka.apache.org/22/documentation/streams/quickstart
Run Kafka Streams Demo Application
이 튜토리얼은 처음 Kafka를 접하시는 분들이 보시면 좋고,
Kafka 나 Zookeeper 데이터가 전혀 없는 상태라는 가정을 하며 진행하도록 하겠습니다.
앞서 Kafka Download 나 Server를 실행한 이력이 있다면, 아래 두 단계는 스킵하시면 됩니다.
Kafka Stream은 미션 크리티컬한 실시간 어플리케이션이나 마이크로 서비스등을 구축하는 용도의 클라이언트 라이브러리 입니다.
또한 입출력 데이터를 Kafka Cluster에 저장합니다.
Kafka Stream은 작성시 단순성, 어플리케이션간의 높은 확장, 탄력, 내결함성, 분산 등의 Kafka의 서버측 클러스터 기술의 모든 혜택과
클라이언트 측에 표준 자바 와 스칼라 어플리케이션의 배포가 융합되어 있습니다.
이 quickstart 예제는 라이브러리상에 코딩된 스트리밍 어플리케이션을 실행하는 방법에 대해서 설명을 합니다.
아래, WordCountDemo 예제 코드가 있습니다.( 읽기 쉽게 하기 위해 Java 8 람다식을 사용하기 위해 변환되었습니다.)
|
// Serializers/deserializers (serde) for String and Long types final Serde<String> stringSerde = Serdes.String(); final Serde<Long> longSerde = Serdes.Long(); // Construct a `KStream` from the input topic "streams-plaintext-input", where message values // represent lines of text (for the sake of this example, we ignore whatever may be stored // in the message keys). KStream<String, String> textLines = builder.stream("streams-plaintext-input", Consumed.with(stringSerde, stringSerde); KTable<String, Long> wordCounts = textLines // Split each text line, by whitespace, into words. .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))) // Group the text words as message keys .groupBy((key, value) -> value) // Count the occurrences of each word (message key). .count() // Store the running counts as a changelog stream to the output topic. wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long())); |
해당 어플리케이션에서는 입력 문장에서 단어 발생 히스토그램을 계산해 내는 WordCount 알고리즘을 구현합니다.
그러나, 이전에 봤던, 다른 WordCount 예제와는 다르게, 한정된 데이터를 처리하나,
WordCount 데모 어플리케이션은 이것과는 조금 달리 동작하는데,
무한의, 무한정된 데이터 스트림상에서 동작하도록 설계된 부분이 있습니다.
한정된 변수와 동일하게, 단어수를 추적 및 업데이트 하는 상태를 가지고 있는 알고리즘 입니다.
하지만, 무한정된 입력 데이터에 대한 가능성을 염두해둬야 하므로,
"모든" 입력 데이터를 처리했을때 더 많은 데이터를 처리해야 할지에 대해 알수 없기 때문에,
현재 상태와 결과를 주기적으로 출력합니다.
그럼 우선 첫번째 단계로, Kafka를 시작하고(아직 시작하지 않은 경우),
Kafka topic에 입력데이터를 준비합니다. 그 후에(subsequently) Kafka Stream 어플리케이션에서 처리합니다.
Step 1 : 다운로드
kafka 설치파일을 다운받아 아래와 같이 압축을 풀어주시면 되겠습니다.
https://www.apache.org/dyn/closer.cgi?path=/kafka/2.2.0/kafka_2.12-2.2.0.tgz)
> tar -xzf kafka_2.12-2.2.0.tgz
> cd kafka_2.12-2.2.0
Step 2 : 서버 시작
Kafka는 Zookeeper를 사용하니, 먼저 Zookeeper를 시작하고 나서, Kafka server를 시작 해 주시길 바랍니다.
PS D:\kafka> .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
PS D:\kafka> .\bin\windows\kafka-server-start.bat .\config\server.properties
Step 3 : 입력 토픽 준비하고 Kafka producer 시작하기
"streams-plaintext-input" 입력 토픽과 "stream-plaintext-output" 출력 토픽을 생성합시다.
(주의) compaction 을 활성화하여 output 토픽을 하는데 그 이유는 출력 스트림이 변경이력 스트림이기 때문입니다.
PS D:\kafka> .\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic streams-plaintext-input
PS D:\kafka> .\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic streams-wordcount-output --config cleanup.policy=compact
생성된 토픽은 동일한 kafka-topics 툴을 이용해서 확인할 수 있습니다.
(application output에 대한 설명 : https://kafka.apache.org/22/documentation/streams/quickstart#anchor-changelog-output )
PS D:\kafka> .\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --describe
Topic:streams-plaintext-output PartitionCount:1 ReplicationFactor:1 Configs:cleanup.policy=compact,segment.bytes=1073741824
Topic: streams-plaintext-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:segment.bytes=1073741824
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Step 4: Wordcount 어플리케이션 시작하기
어플리케이션을 시작해 보도록 합시다.
아래 명령은 WordCount demo application을 시작합니다.
PS D:\kafka> .\bin\windows\kafka-run-class.bat org.apache.kafka.streams.examples.wordcount.WordCountDemo
이 어플리케이션은 streams-plaintext-input 이라는 입력 토픽에서 읽어서,
각각의 읽은 메시지에 대해 WordCount 알고리즘의 계산을 실행하고,
지속적으로 현재 결과를 출력 토픽인 streams-wordcount-output에 작성합니다.
따라서, 결과가 Kafka에 다시 작성되는 로그 엔트리를 제외하고 STDOUT 출력은 없을 것입니다.
이제 몇가지 입력 데이터를 이 토픽에 작성하기 위해 별도 터미널에서 console producer를 시작하겠습니다.
PS D:\kafka> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic streams-plaintext-input
별도에 터미널에서 실행된 console consumer에서 출력 토픽을 읽음에 따라서,
WordCount 데모 어플리케이션의 출력을 살펴볼 수 있습니다.
PS D:\kafka> .\bin\windows\kafka-console-consumer.bat
--bootstrap-server localhost:9092
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.DefaultMessageFormatter
--property print.key=true
--property print.value=true
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
Step 5: 데이터 처리하기
이제 console producer을 이용해서, 텍스트 한 줄을 입력하고 엔터를 치는 것으로, streams-plaintext-input 이라는 입력 토픽에 메세지를 작성해 봅시다.
이건 새로운 메세지를 입력 토픽에 보내게 됩니다.
그 메세지 키는 null이고 메세지 값은 바로 입력된 인코딩된 텍스트 라인 스트링입니다.
(실제로, 어플리케이션에 대한 입력 데이터는 quickstart에서 우리가 했던 것 처럼 수동으로 입력하는 것 대신 Kafka안으로 지속적으로 스트리밍될 것입니다. )
PS D:\kafka> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka
이 메세지는 Wordcount 어플리케이션에 의해 처리되고,
다음 출력데이터는 "streams-wordcount-output"에 작성되고, console consumer에 의해 출력될 것입니다.
PS D:\kafka> .\bin\windows\kafka-console-consumer.bat
--bootstrap-server localhost:9092
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.DefaultMessageFormatter
--property print.key=true
--property print.value=true
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
여기 첫번째 컬럼은 포멧이 java.lang.String인 Kafka 메세지 키 이고 카운트되고 있는 단어를 나타냅니다.
그리고 두번째 컬럼은 포멧이 java.lang.Long 인 메시지 값이고, 단어의 최신 카운트를 나타냅니다.
자, 입력 토픽인 streams-plaintext-input안에 console producer를 이용해 하나 더 메세지를 작성해봅시다.
"hello kafka streams"을 입력하고 엔터를 치면, 터미널에서는 아래와 같이 확인이 가능합니다.
PS D:\kafka> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka
>hello kafka streams
console consumer가 실행중인 다른 터미널에서, 새로운 출력 데이터를 작성된 WordCount 어플리케이션을 볼수 있습니다.
PS D:\kafka> .\bin\windows\kafka-console-consumer.bat
--bootstrap-server localhost:9092
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.DefaultMessageFormatter
--property print.key=true
--property print.value=true
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
마지막으로 출련된 라인인 to 2 와 kafka 2 는 kafak 와 streams 키의 카운트가 1에서 2로 증가가 업데이트된 것을 나타냅니다.
입력 토픽에 더 많은 입력 메세지를 작성할 때마다, streams-wordcount-output 토픽에 추가되는 새로운 메시지들을 확인할 수 있습니다.
가장 최신의 단어 개수가 WordCount 어플리케이션에 의해 계산되어 나타냅니다.
quickstart를 마무리(wrap up)하기 전에 마지막 최종 입력 문자 라인인 "join kafka summit" 을 입력하고 console producer에 엔터를 치면,
입력 토픽 streams-wordcont-input에 <RETURN>을 실행해봅시다.
PS D:\kafka> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic streams-plaintext-input
>all streams lead to kafka
>hello kafka streams
>join kafak summit
streams-wordcount-output 토픽은 이어서 일치하는 업데이트된 단어 개수를 보여줍니다. (마지막 3개 단어)
PS D:\kafka> .\bin\windows\kafka-console-consumer.bat
--bootstrap-server localhost:9092
--topic streams-wordcount-output
--from-beginning
--formatter kafka.tools.DefaultMessageFormatter
--property print.key=true
--property print.value=true
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
join 1
kafka 3
summit 1
보다시피, Wordcount 어플리케이션의 출력은 실제로 지속적인 업데이트의 스트림이고,
각 출력 레코드(예를 들어 위의 원본 출력에서 각 라인)은 단일단어의 업데이트된 카운트이고, 레코드키는 "kafka" 같은 것입니다.
같은 키를 갖는 다수의 레코드에 대해서, 각 이후 레코드는 이전 레코드의 업데이트본입니다.
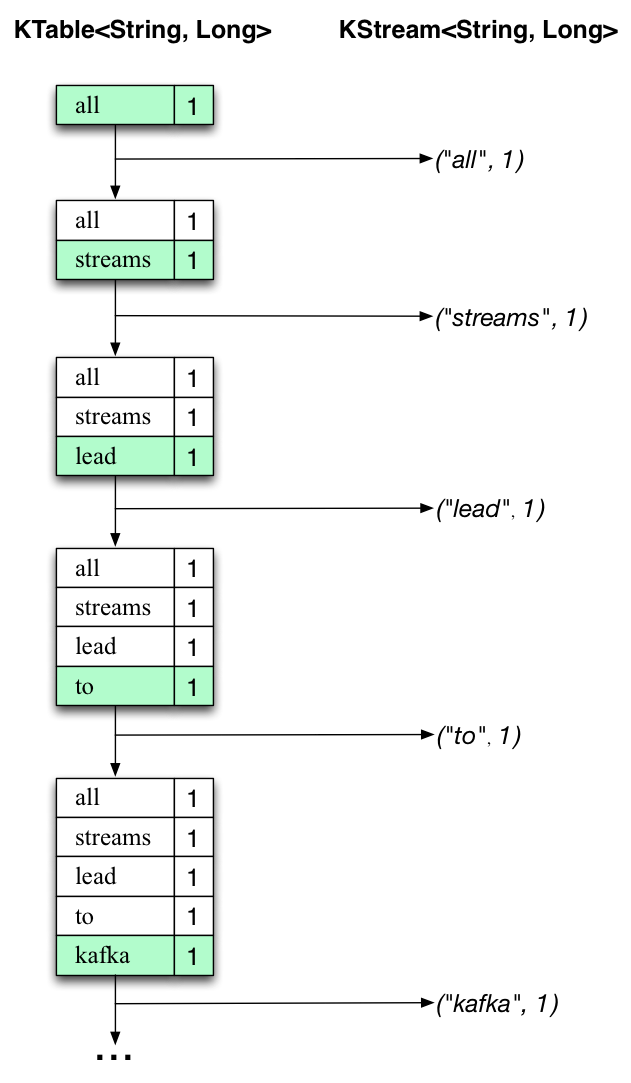

위에 두 다이어그램이 무슨일이 실제로 일어나는지를 설명하고 있다.
첫번째 컬럼은 count에 대한 단어 발생 카운팅하는 KTable<String, Long> 의 현재 상태의 진화를 보여준다.
두번째 열은 KTable에 대한 상태 업데이트로 인한 변경 기록을 보여주고,
streams-wordcount-output 출력 Kafka 토픽에 보내집니다.
첫번째 텍스트 라인 "all streams lead to kafka"은 처리됩니다.
KTable은 새로운 테이블 엔트리(녹색 배경으로 하이라이트됨)에 각기 새로운 단어 결과들로써 빌드업되어지고
일치하는 변경 기록은 KStream 다운스트림에 보내집니다.
두번째 라인 "hello kafka streams"이 처리될 때, 처음으로 KTable에 존재하는 엔트리들이 업데이트되어지는 것을 관찰합니다.
(여기, kafka 와 stream 단어들) 그리고 다시, 변경 기록들은 출력 토픽에 보내집니다.
출력토픽이 변경 전체 기록을 포함하기 때문에, 위에서 우리가 보여준 내용을 가지고 있는지를 설명합니다.
이 구체적인 예제의 범위를 넘어서, Kafka Streams가 여기서 하고 있는 일은 테이블과 변경로그 스트림간의 이중성을 활용하기 위한것입니다.
(여기서 table 은 KTable , changelog stream 은 downstream KStream)
스트림에 테이블의 모든 변경을 게시할수 있고, 완전한 변경로그 스트림을 시작부터 끝까지 소비한다면,
여러분은 테이블의 내용을 재구성할수 있습니다.
Step 6 : 어플리케이션 해제하기
console consumer, console producer, Wordcount 어플리케이션, 카프카 브로커 그리고 Zookeeper 서버를 Ctrl+C를 통해 순서대로
멈출수 있습니다.
끝
'해보자 > Kafka' 카테고리의 다른 글
| Kafka 한번 살펴보자... Quickstart (1) | 2019.06.21 |
|---|---|
| Kafka 한번 살펴보자... Introduction (402) | 2019.06.21 |